CVPR 2020
Paper | Code | Google Scholar | bibtex
Abstract
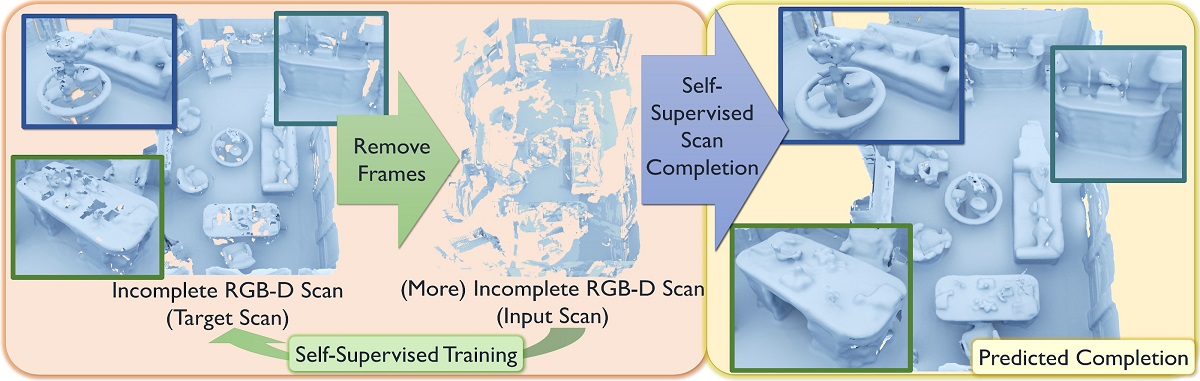
We present a novel approach that converts partial and noisy RGB-D scans into high-quality 3D scene reconstructions by inferring unobserved scene geometry. Our approach is fully self-supervised and can hence be trained solely on real-world, incomplete scans. To achieve self-supervision, we remove frames from a given (incomplete) 3D scan in order to make it even more incomplete; self-supervision is then formulated by correlating the two levels of partialness of the same scan while masking out regions that have never been observed. Through generalization across a large training set, we can then predict 3D scene completion without ever seeing any 3D scan of entirely complete geometry. Combined with a new 3D sparse generative neural network architecture, our method is able to predict highly-detailed surfaces in a coarse-to-fine hierarchical fashion, generating 3D scenes at 2cm resolution, more than twice the resolution of existing state-of-the-art methods as well as outperforming them by a significant margin in reconstruction quality.